Birds of a feather flock together
"Birds of a feather flock together"는 영어 속담입니다. 이 문장을 그대로 해석하면 “같은 깃털을 가진 새들은 함께 모인다”라는 뜻입니다.
이 속담은 비슷한 성향, 취향, 가치관, 배경을 가진 사람들끼리 자연스럽게 모이는 경향이 있다는 것을 의미합니다.
즉, 사람들이 자신과 비슷한 성격이나 관심사를 가진 사람들과 친해지고 함께 어울린다는 뜻이죠.
우리말로 표현하면 “끼리끼리 논다, “유유상종이다”와 같은 의미입니다.
You can see that birds of a feather flock together when you look at student groups in school.
(학교에서 학생 그룹을 보면 끼리끼리 논다는 걸 알 수 있다.)
My friends and I love reading, I guess birds of a feather flock together.
(내 친구들과 나는 모두 책 읽기를 좋아한다. 그러니까 결국 유유상종이네.)
K-NN 알고리즘이란?
K-NN 알고리즘은 머신러닝에서 가장 기본적인 분류(Classification), 회귀(Regression)기법 중 하나입니다.
- 새로운 데이터가 주어지면, 기존 데이터 중에서 가장 가까운(유사한) K개의 이웃을 찾고
- 그 이웃들이 가진 특성(레이블, 값 등)에 따라 새로운 데이터의 분류를 예측합니다.
예를 들어, 붓꽃 데이터를 가지고 꽃의 종류를 분류할 때, 미지의 꽃이 여러 '이웃' 중 어떤 그룹에 더 많이 속하는지를 판단해 클래스를 결정합니다.
속담과의 연관성
"Birds of a feather flock together"는 K-NN 알고리즘의 기본 원리를 아주 직관적으로 비유한 말과도 같습니다.
- 현실: '깃털이 같은' (즉, 비슷한 특징을 가진) 새들끼리 모여서 한 무리를 이룸
- K-NN: 유사한 데이터는 서로 가까이 위치(거리 상)하고, 새로운 데이터도 '가장 가까운' 이웃 그룹(majority group)으로 분류됨
'특징이 비슷한 새들이 모인다' = '비슷한 특성을 가진 데이터들이 같은 클래스로 분류된다'
구체적인 예시
만약 학생 A의 성적, 취미와 같은 특징들이 있다면,
- K-NN은 A와 가장 비슷한 K명의 학생을 찾아 각각의 그룹(예: 동아리, 반, 친구 그룹 등) 중 어디에 속할 확률이 높은지 예측합니다.
- Birds of a feather flock together: 즉, 비슷한 사람들이 결국 비슷한 그룹에 모이는 법이라는 관점에서, "K-NN 알고리즘은 같은 속성을 가진 데이터 포인트들이 한 그룹을 이룬다는" 전제 하에 작동한다고 볼 수 있습니다.
K-NN 알고리즘은 “비슷한 것들끼리 모인다(Birds of a feather flock together)”는 원리를 수학적으로 구현한 것이라고 할 수 있습니다!
될성부른 나무는 떡잎부터 알아본다.
이 속담은 훌륭하게 자랄 나무는 아주 어릴 때부터 남다른 싹(떡잎)을 보인다는 뜻입니다. 즉, 앞으로 크게 될 사람이나 사물은 어린 시절이나 초기 단계부터 남다른 기운이나 재능이 드러난다는 의미입니다.
우리말 풀이
- 어린아이라도 장래에 크게 될 인물은 어릴 때부터 달라 보인다.
- 초기 단계에서 가능성이나 뛰어난 자질을 엿볼 수 있다.
- 비슷한 뜻의 속담: “호랑이 새끼는 어릴 때부터 다르다”, “작은 고추가 맵다” (약간은 다르지만 비슷한 의미로 쓰일 때가 있음)
예시
- 어린아이지만 남다른 집중력과 재능을 보였던 축구 선수 손흥민은 “될성부른 나무는 떡잎부터 알아본다”는 말을 떠올리게 한다.
- 이제 막 사업을 시작했지만, 참신한 아이디어와 열정이 남달라서 “될성부른 나무는 떡잎부터 알아본다”고 할 만하다.
영어로 표현
이 속담과 비슷한 영어 속담은 다음과 같습니다.
The child is father of the man.
(아이는 어른의 아버지다 → 아이의 성격이 그대로 어른이 됨)
The proof of the pudding is in the eating.
(결과는 처음 단계에서 드러난다. 다만 완전히 일치하지는 않음)
K-최근접 이웃(K-NN Algorithm)
[머신러닝] K-NN 알고리즘 (K-최근접 이웃) 개념
K-NN 알고리즘 (K-최근접 이웃) 개념 편 될성부른 나무는 떡잎부터 알아본다 모든 기업들에게 'V...
blog.naver.com
모든 기업들에게 'VIP' 고객은 너무나도 중요합니다. 실제로 현업에서도 'VIP' 고객을 확보하기 위해 많은 마케팅 비용과 자원을 투입하게 됩니다.
VIP 고객이 우리의 서비스를 이용하고 VIP로 성장하기까지 그들은 어떤 모습으로 어떻게 우리의 서비스를 이용했을까? 과연 그들은 초기 사용 때부터 떡잎부터 달랐을까?
그렇다면 새롭게 들어온 신규고객 중 VIP가 될 수 있는
'떡잎'을 찾아서 빨리, 더 많이 '될성부른 나무'로 키울 수 있지 않을까?
이러한 관점에서 'VIP'로 성장할 가능성이 높고, VIP 고객의 초기 사용 패턴과 유사한 속성의 '신규 고객'을 찾는 방법으로 제가 활용하였던 알고리즘이 있습니다.
바로 'K-NN 알고리즘(K-최근접 이웃)'입니다.
'K-NN 알고리즘'이 무엇인지 간단한 설명을 통해 개념을 소개하고, 'K-NN 알고리즘'을 이용한 분석 사례에 대해 소개합니다.
'같은 날개를 가진 새들끼리 함께 모인다'라는 뜻의 '유유상종'은 'K-NN 알고리즘'을 설명하기 좋은 속담이라고 생각합니다. 'K-NN 알고리즘'은 머신러닝에서 데이터를 가장 가까운 유사 속성에 따라 분류하여 데이터를 분류하는 기법입니다.
- 예를 들어, A라는 사람과 가장 유사한(가까운) 속성을 지닌 사람이 '영웅(Hero)'이라고 하면, A는 '영웅'일 것이다라고 추정하는 방식입니다.
- 만약, A가 '빌런 (Villain)'과 가까운 속성을 가지고 있다면 A를 '빌런'일 것이다라고 추정할 수 있습니다.
K-NN은 머신러닝에서 지도 학습(Supervised Learning)에 한 종류로 거리기반 분류분석 모델이라고 할 수 있습니다.
- 거리기반으로 분류를 하는 '클러스터링 (Clustering)'과 유사한 개념이긴 하나, 기존 관측치의 Y값(Class)가 존재한다는 점에서 비지도학습 (Unsupervised Learning)'에 해당하는 '클러스터링'과 차이가 있습니다.
위에서 'K-NN'을 거리기반 분류분석 모델이라고 말씀 을 드렸습니다. 'K-NN'은 데이터로부터 거리가 가까운 'k'개의 다른 데이터의 레이블을 참조하여 분류하는 알고리즘입니다.
- 이 때, 데이터 간 거리를 측정할 때 '유클리디안 거리' 계산법을 사용합니다.
- '유클리디안 거리' 계산은 우리가 학창시절에 배웠던 피타고라스의 정리를 생각하시면 됩니다.
K-NN은 이처럼 너무 간단한 알고리즘이지만 실제로 이 미지 처리, 영상에서 글자 인식과 얼굴 인식 그리고 영화, 음악, 상품 추천 알고리즘으로도 사용되며, 의료 분야나 생명 과학 분야에서 유전자 데이터의 패턴 인식이나 암 진단 등에도 사용되고 있습니다. 제가 위에서 소개한 VIP 가망 신규 고객을 분류하는 방식으로도 이 알고리즘을 사용할 수 있습니다.

K-NN 알고리즘의 작동 방식에 대해 간단한 예로 설명 을 드리도록 하겠습니다. 위 그림에서 A라는 사람의 '짜장 vs 짬뽕'의 선호도를 예측한다고 가정하겠습니다. 짜장을 선호할지, 짬뽕을 선호할 지에 대해 미치는 여러 변수가 있겠으나, 간단한 설명을 위해 2차원의 2가지 변수만 고려를 해보겠습니다.
먼저 Y축의 변수는 단맛 선호의 정도를 나타냅니다. 대체적으로 '단맛'을 선호하는 사람들은 '짜장'면을 선호하는 경향을 보이는 것 같습니다. X축은 매운맛 선호의 정도를 나타냅니다. 대체적으로 '짬뽕'을 선호라는 사람들은 매운맛을 선호하는 것을 볼 수 있습니다.
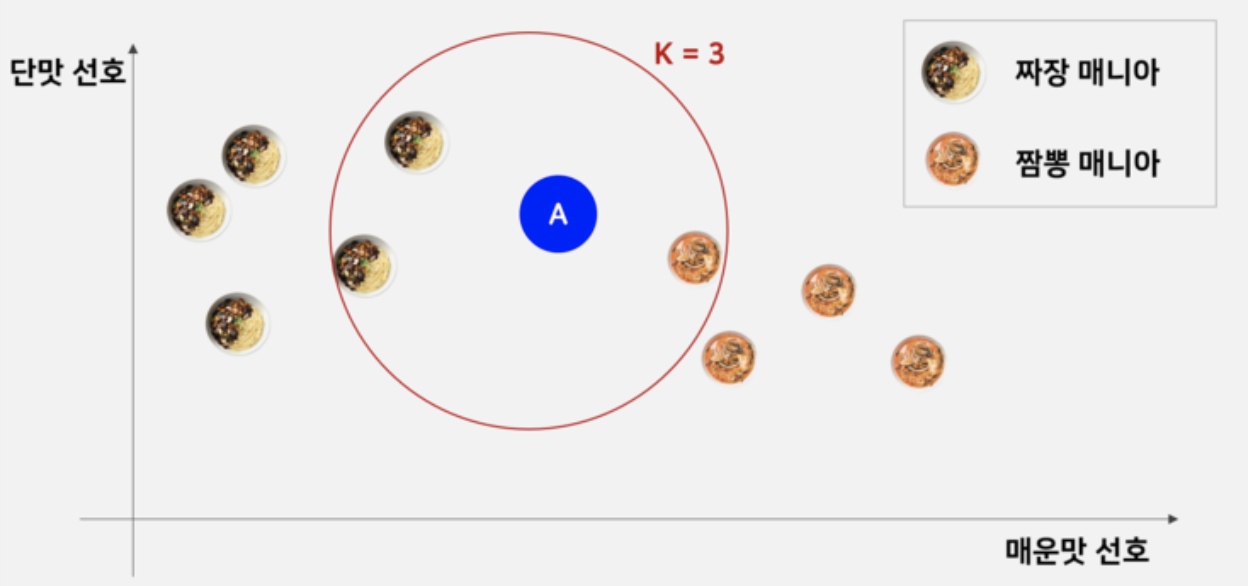
이제 K-NN 알고리즘을 이용하여 A와 가장 가까운 거리에 있는 3개의 데이터를 찾아보도록 하겠습니다. 위 그림에서 보면 거리상으로 가장 가까운 데이터는 짬뽕인 것을 알 수 있습니다. 그러나 3개의 데이터의 다수를 차지하는 것은 '짜장'인 것을 알 수 있습니다. 이때, k=1이었다면 A는 짬뽕을 선호하는 데이터로 분류가 되었겠지만, k=3 일 때, A는 '짜'을 선호하는 데이터로 분류가 됩니다. 이것이 'K-NN 알고리즘'의 작동 방식입니다.
K-NN 알고리즘을 이용할 때, k의 개수는 홀수로 지정하는 것이 좋습니다. 그 이유는 짝수로 지정하였을 때 동점 상황이 만들어지면서 데이터를 분류할 수 없는 상황이 생길 수 있기 때문입니다.
- 위 그림에서 K=4라고 하였을 때, 짜장 2, 짬뽕 2의 동점 상황이 생깁니다. 이때 A를 짜장을 선호하는지 짬뽕을 선호하는지 판단할 수 없게 됩니다.
K-NN 알고리즘의 특성
K-NN 알고리즘은 너무나 간단한 알고리즘이지만, 실제로 이미지 처리, 글자/얼굴 인식, 추천 알고리즘, 의료 분야 등에서 많이 사용됩니다.
우선 장점으로는 단순하기 때문에 다른 알고리즘에 비해 구현하기가 쉽고, 훈련 데이터를 그대로 가지고 있어 특별한 훈련을 하지 않기 때문에 훈련 단계가 매우 빠르게 수행된다는 특징이 있습니다.
다만, 단점으로는 모델을 생성하지 않기 때문에 특징과 클래스 간 관계를 이해하는데 제한적이며, 모델의 결과를 가지고 해석하는 것이 아니라, 미리 변수와 클래스 간의 관계를 파악하여 이를 알고리즘에 적용해야 원하는 결과를 얻을 수 있기 때문입니다.
또, 적절한 K의 선택이 필요하고, 훈련 단계가 빠른 대신 데이터가 많아지면 분류 단계가 느려지는 특징이 있습니다.
예를 들면, 한 사람의 취향을 분석하기 위해서 그 사람의 가족 관계, 성장 배경, 심리 상태, 연령, 성별 등을 각각 직접 라벨링 하는 것과 같으며 이 데이터를 모아서 학습하는 것이 훈련 단계에 해당하며, 이 관계로 도출된 취향이 결과에 해당한다.











































































































































p.s. 모든 인공지능의 알고리즘의 원리는 인간의 본능과 지능의 작동 방식의 이론화이며 이는 인간의 뇌가 작동하는 방식을 기반으로 한다. 즉 해당 논리들은 전부 당신이 무의식 혹은 의식적으로 이렇게 행동하고 있다는 것을 설명한다.
인공지능이 욕설을 하거나 난폭한 행동을 한다면 이 또한 인간이 가르친 것이다.
'아현' 카테고리의 다른 글
| 전쟁의 양상과 전략 혁신, 그리고 사회적 인식의 한계 (2) | 2025.05.03 |
|---|---|
| 고통을 감추는 방법, 인간실격(人間失格) (2) | 2025.05.01 |
| 주인의식? 회사만 좋은 거 아냐?, 비상계엄 이후 금융·경제 영향 평가 (5) | 2025.04.25 |
| 개인과 문화는 서로를 반영하고 강화한다, 한국은 망했다 (4) | 2025.04.22 |
| 고통을 잊는 뇌, 기억하는 마음 (0) | 2025.04.19 |